Types de Variables
Les variables sont classées en fonction de leur niveau de mesure et de leur type de données.
- Variables ID
- Utilisées pour les identifiants uniques (ex. : nom, ID de participant).
- Améliorent les performances avec de grands ensembles de données.
- Variables Nominales
- Variables catégorielles (ex. : Sexe, avec valeurs comme "Homme" et "Femme").
- Peuvent être codées numériquement (ex. : 1 = Homme, 2 = Femme).
- Utilisées principalement pour des données qualitatives.
- Variables Ordinales
- Variables ayant un ordre spécifique (ex. : échelle de Likert, où 3 = "tout à fait d'accord" et -3 = "tout à fait en désaccord").
- Variables Continues
- Variables qui existent sur une échelle continue (ex. : taille, poids).
- Correspondent aux variables d'intervalle ou de rapport.
Variables Calculées
- Définition : Variables créées en effectuant un calcul sur d'autres variables.
- Exemples d'utilisation :
- Transformations logarithmiques.
- Z-scores.
- Moyennes ou scores sommatifs.
- Ajout d'une variable calculée :
- Accéder au bouton "Ajouter" dans l'onglet Données pour insérer des variables calculées.
- Entrer une formule dans la boîte de calcul. Exemple de formules :
A + B : Somme de A et B.LOG10(len) : Transformation logarithmique de len.MOYEN(A, B) : Moyenne de A et B.(dose - VMEAN(dose)) / VSTDEV(dose) : Z-score pour la variable dose.
Fonctions V
- Fonctions V : Calculent des valeurs sur l'ensemble d'une variable (ex. :
VMEAN(A) pour la moyenne de toutes les valeurs de A). - Fonctions non-V : Calculent des valeurs ligne par ligne (ex. :
MEAN(A, B) pour la moyenne des valeurs A et B dans chaque ligne).
1. Introduction
Les mesures de la tendance centrale sont des statistiques utilisées pour résumer un ensemble de données par une valeur centrale. Les trois mesures les plus courantes sont la moyenne, la médiane et le mode.


Moyenne vs Médiane
- Moyenne : Utilise toutes les valeurs et est sensible aux valeurs extrêmes (outliers).
- Médiane : Ne dépend que du classement des données et est moins influencée par les valeurs extrêmes.
- Exemple concret :
- Revenu de 4 personnes : 50 000, 60 000, 65 000 et 100 000 000.
- Moyenne = 25 043 750, mais médiane = 62 500.
- La moyenne est fortement influencée par la valeur extrême de 100 millions, alors que la médiane reste représentative de la majorité des valeurs.
Quand utiliser la moyenne ou la médiane ?
- Données nominales : La moyenne et la médiane ne sont pas appropriées. Il est préférable d’utiliser le mode (voir section 4.1.6).
- Données ordinales : La médiane est préférée car elle se base sur l’ordre des valeurs sans se soucier des valeurs exactes.
- Données d’échelle d’intervalle ou de rapport : La moyenne et la médiane peuvent être utilisées, mais la moyenne est préférable lorsque les données sont symétriques, et la médiane est préférable pour les distributions asymétriques ou avec des valeurs extrêmes.
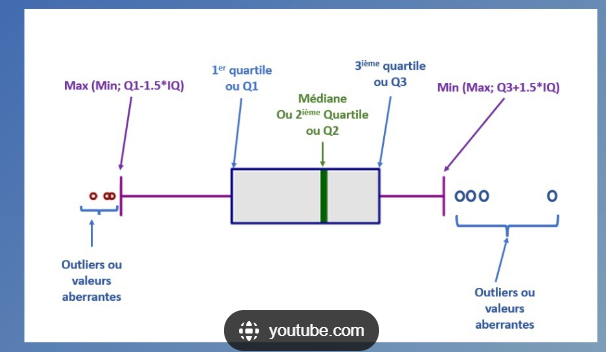
Un percentile est une mesure qui divise un ensemble de données en 100 parts égales. En d'autres termes, un percentile représente la position relative d'une donnée par rapport à l'ensemble des données classées dans un ordre croissant.
Exemple :
Si nous avons un ensemble de données et que nous calculons le 50e percentile (ou médiane), cela signifie que 50 % des données se trouvent en dessous de cette valeur et 50 % se trouvent au-dessus.
De manière générale, le p-ème percentile est une valeur de donnée en dessous de laquelle p % des données se trouvent. Par exemple :
- Le 25e percentile (ou 1er quartile), est la valeur en dessous de laquelle se trouvent 25 % des données.
- Le 75e percentile (ou 3e quartile), est la valeur en dessous de laquelle se trouvent 75 % des données.
Définition :
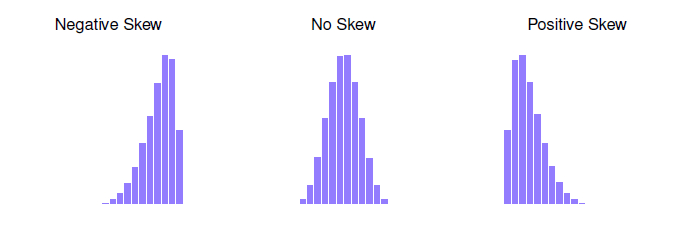
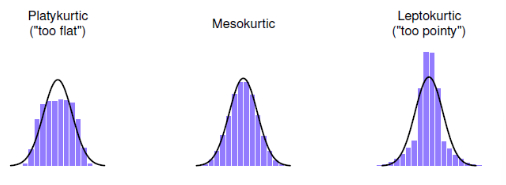
L'aplatissement (ou kurtosis) mesure l'acuité de la distribution des données, c'est-à-dire à quel point elles sont "pointues" ou "plates". Cela évalue la concentration des données autour de la moyenne et la hauteur de leurs queues.
Types de kurtosis :
- Platykurtique (kurtosis négatif) :
- Les données sont trop plates.
- La distribution a des queues plus petites que celles de la courbe normale.
- Exemples : moins de valeurs extrêmes (valeurs proches de la moyenne).
- Mésokurtique (kurtosis = 0) :
- La distribution est normalement distribuée.
- C'est le cas de la courbe normale, où les données sont bien réparties autour de la moyenne.
- Exemples : distribution standard comme une courbe de Gauss.
- Leptokurtique (kurtosis positif) :
- Les données sont trop pointues.
- La distribution a des queues plus longues et plus hautes que celles de la courbe normale.
- Exemples : plus de valeurs extrêmes, données plus concentrées autour de la moyenne.
Interprétation du kurtosis :
- Kurtosis négatif (platykurtique) : Les données sont trop plates.
- Kurtosis égal à 0 (mésokurtique) : Les données suivent une distribution normale.
- Kurtosis positif (leptokurtique) : Les données sont trop pointues.

1. Statistiques descriptives par groupe
Il est souvent utile d'examiner les statistiques descriptives séparément pour chaque groupe, comme par exemple dans une étude de traitement. On peut ventiler les statistiques par une variable de regroupement, telle que le type de thérapie, pour mieux comprendre les différences.
- Exemple : Si on veut examiner les données sur le gain d'humeur (mood.gain) en fonction de la thérapie reçue (placebo, anxifree, joyzepam, TCC), on peut utiliser Jamovi pour obtenir des statistiques comme la moyenne, l'écart-type, l'asymétrie, et l'aplatissement.
- Plusieurs variables de regroupement : On peut ajouter d'autres variables (ex. : médicament) dans la case « Split by » pour examiner les statistiques pour chaque combinaison de groupes. Cependant, attention, si les groupes deviennent trop petits, des valeurs comme NaN ou Inf peuvent apparaître.